Lambda Event Handler
Now that we have the Kendra index and the data source, we will configure a lambda event handler for the bucket used as a data source. We will use separate folders for user blogs, guides, case studies, analyst reports and white papers. The lambda function will set the appropriate access attributes and DocumentType attribute based on the folder where the document is put in the bucket.
We will use a separate folder for Images. When a png file containing an image is copied to this folder, the lambda function will make a call to Amazon Textract and extract the text before ingesting the document in the Kendra index.
Please note that there are many ways to ingest the documents in the index, by calling the Kendra API from any of the supported languages or the AWS CLI. However in this lab the use of Lambda is being demonstrated since Lambda can come quite handy for many other use cases where there is a need to call other services such as Amazon Textract to extract text from an image file or Amazon Transcribe to get transcription from an audio file and ingesting appropriate text in the Kendra index.
Create Lambda Function
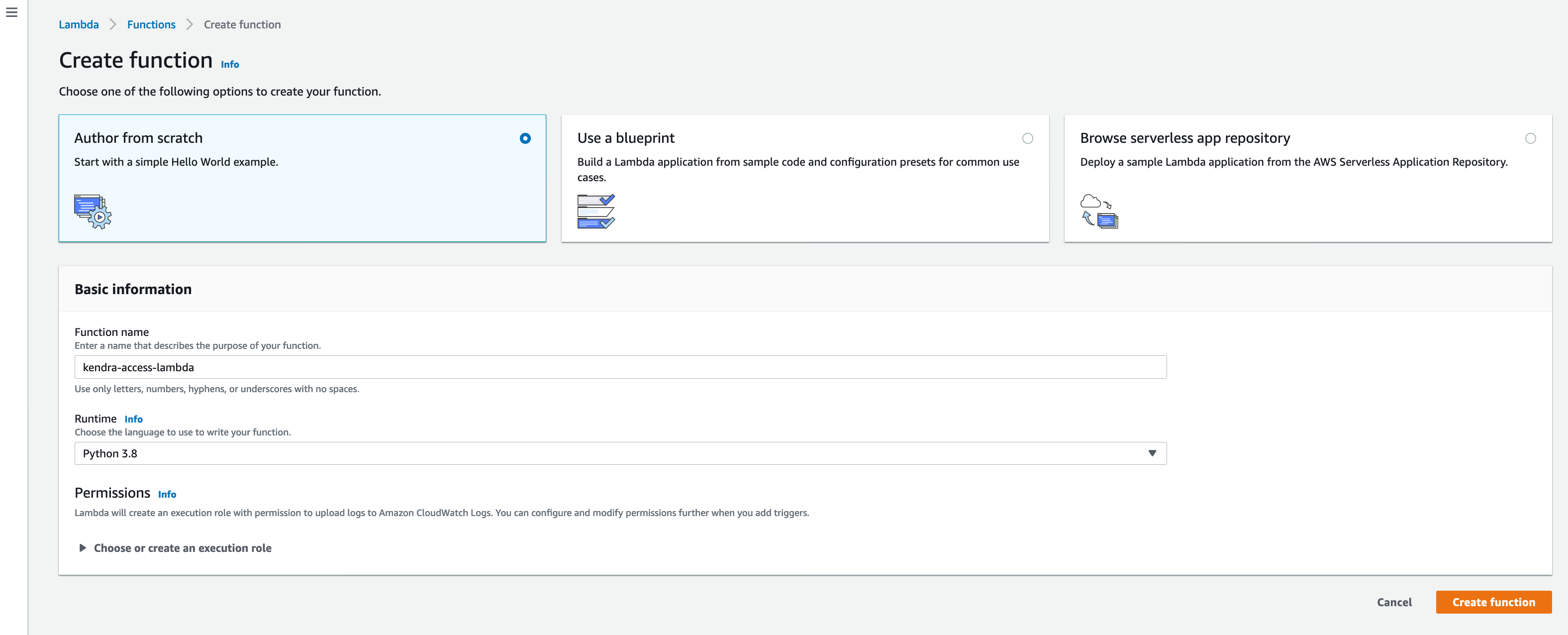
- In AWS Management Console browse to Lambda and click on Create function
- Choose Author from scratch, give a Function name such as kendra-access-lambda
- Choose the Runtime as Python 3.8 and click on Create function. This should look as like the screenshot below:
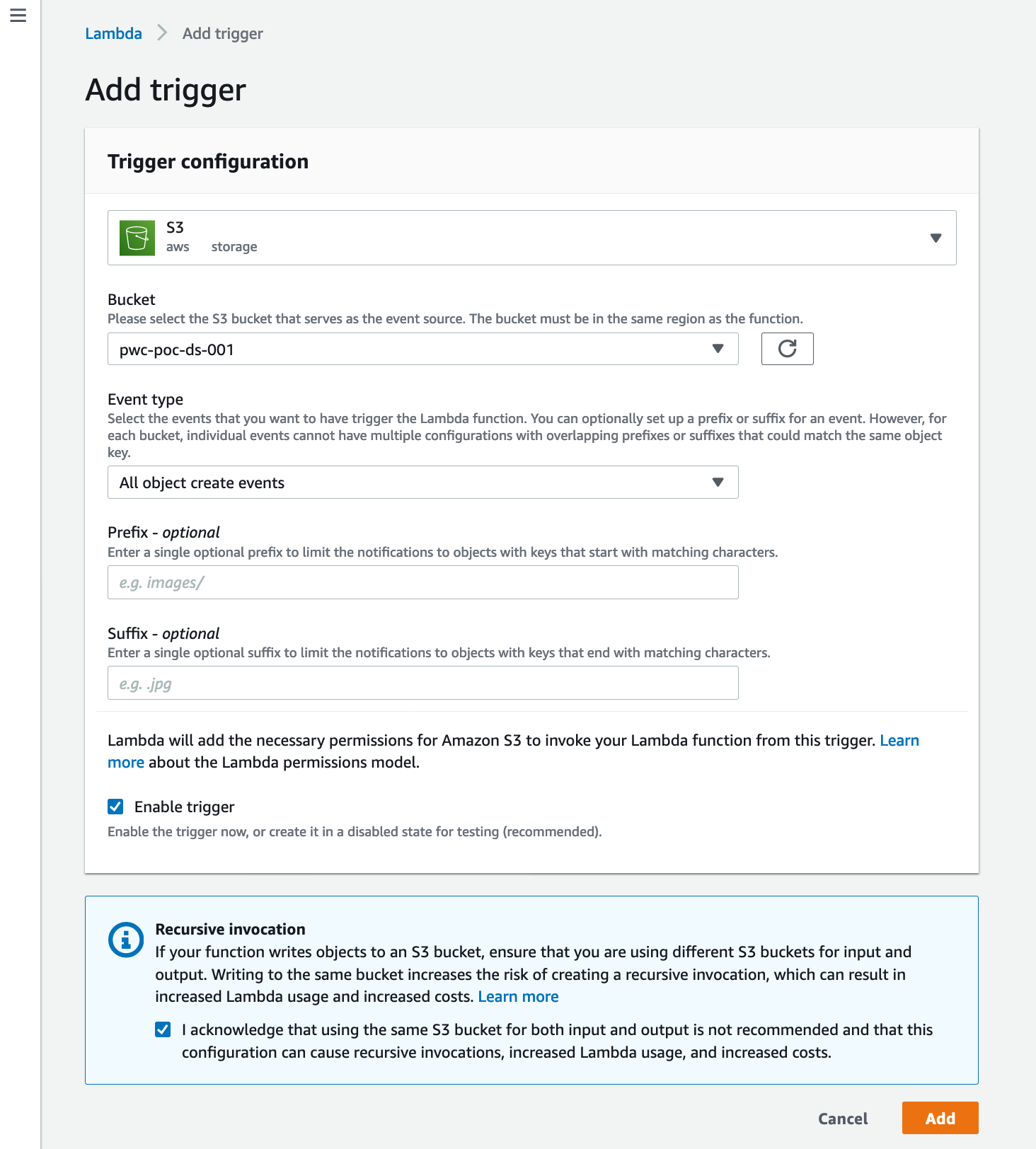
- Click on Add trigger, select S3, select the bucket configured as data source. Keep Enable trigger checked. Click Add. This will look as below:
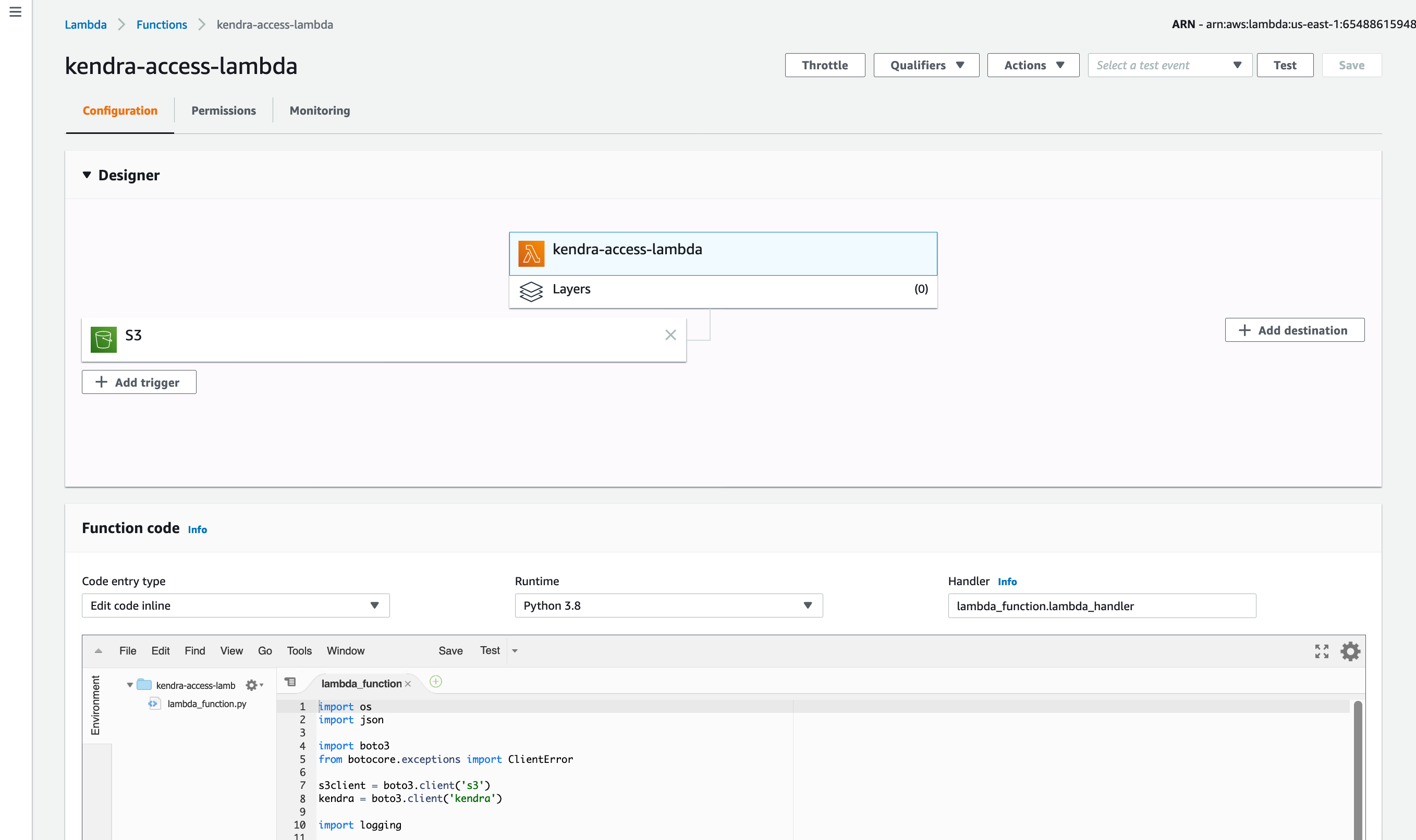
- Back in the designer click on the lambda function name. In the Function code window replace existing code with the code from the block below. Replace REPLACE-WITH-YOUR-INDEX-ID and REPLACE-WITH-DATASOURCE-ARN in the code appropriately from the values you have copied in your note pad. Click on Save.:
import os
import json
import boto3
import logging
from botocore.exceptions import ClientError
s3client = boto3.client('s3')
kendra = boto3.client('kendra')
teclient = boto3.client('textract')
logger = logging.getLogger()
logger.setLevel(logging.INFO)
index_id = "REPLACE-WITH-YOUR-INDEX-ID"
role_arn = "REPLACE-WITH-DATASOURCE-ROLE-ARN"
#Event handler for S3 bucket to update the kendra index with the document details for a newly uploaded document
def image_handler(bucket, key):
key_split = key.split('/')
key_len = len(key_split)
doc_name = key_split[key_len-1]
if (doc_name.lower().endswith(".png")):
logger.info("Received Image File: %s", doc_name)
response = teclient.detect_document_text(
Document={'S3Object': {'Bucket': bucket, 'Name': key}})
output = ''
for b in response['Blocks']:
if (b['BlockType'] == 'LINE'):
output = output + '\n' + b['Text']
doc_type = 'Image-textract'
documents = [
{
"Id": doc_name,
"Title": doc_name,
"Blob": output,
"Attributes": [
{
"Key": "DocumentType",
"Value": {
"StringValue": doc_type
}
},
{
"Key": "_source_uri",
"Value": {
"StringValue": "https://s3.us-east-1.amazonaws.com/" + bucket + '/' + key
}
}
]
}
]
result = kendra.batch_put_document(
IndexId = index_id,
RoleArn = role_arn,
Documents = documents
)
logger.info("kendra.batch_put_document: %s" % json.dumps(documents))
logger.info("result: %s" % json.dumps(result))
else:
logger.info("Not a png document. Ignore")
def access_handler(bucket, key):
key_split = key.split('/')
key_len = len(key_split)
doc_name = key_split[key_len-1]
doc_type = key_split[1]
if (doc_type == "user-guides"):
acclist = [
{ "Access": "ALLOW", "Name": "customer", "Type": "GROUP" },
{ "Access": "ALLOW", "Name": "AWS-Sales", "Type": "GROUP" },
{ "Access": "ALLOW", "Name": "AWS-Marketing", "Type": "GROUP" },
{ "Access": "ALLOW", "Name": "AWS-SA", "Type": "GROUP" },
]
elif (doc_type == "case-studies"):
acclist = [
{ "Access": "ALLOW", "Name": "AWS-Sales", "Type": "GROUP" },
{ "Access": "ALLOW", "Name": "AWS-Marketing", "Type": "GROUP" },
{ "Access": "ALLOW", "Name": "AWS-SA", "Type": "GROUP" },
]
elif (doc_type == "analyst-reports"):
acclist = [
{ "Access": "ALLOW", "Name": "AWS-Marketing", "Type": "GROUP" },
{ "Access": "ALLOW", "Name": "AWS-SA", "Type": "GROUP" },
]
elif (doc_type == "white-papers"):
acclist = [
{ "Access": "ALLOW", "Name": "AWS-SA", "Type": "GROUP" },
]
elif (doc_type == "blogs"):
acclist = [
{ "Access": "ALLOW", "Name": "ANONYMOUS", "Type": "GROUP" },
]
else:
acclist = [
{ "Access": "ALLOW", "Name": "AWS-SA", "Type": "GROUP" },
]
documents = [
{
"Id": doc_name,
"Title": doc_name,
"S3Path": {
"Bucket": bucket,
"Key": key
},
## Simplistic logic to use the middle part of the prefix as the DocumentType
"Attributes": [
{
"Key": "DocumentType",
"Value": {
"StringValue": doc_type
}
},
{
"Key": "_source_uri",
"Value": {
"StringValue": "https://s3.us-east-1.amazonaws.com/" + bucket + '/' + key
}
}
],
"AccessControlList": acclist
}
]
result = kendra.batch_put_document(
IndexId = index_id,
RoleArn = role_arn,
Documents = documents
)
logger.info("result: %s" % json.dumps(result))
def lambda_handler(event, context):
logger.info("Received event: %s" % json.dumps(event))
for record in event['Records']:
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
if (key.startswith('Images')):
image_handler(bucket, key)
elif (key.startswith('Data')):
access_handler(bucket, key)
else:
logger.info("File not from Data or Image folders")
This should look like:

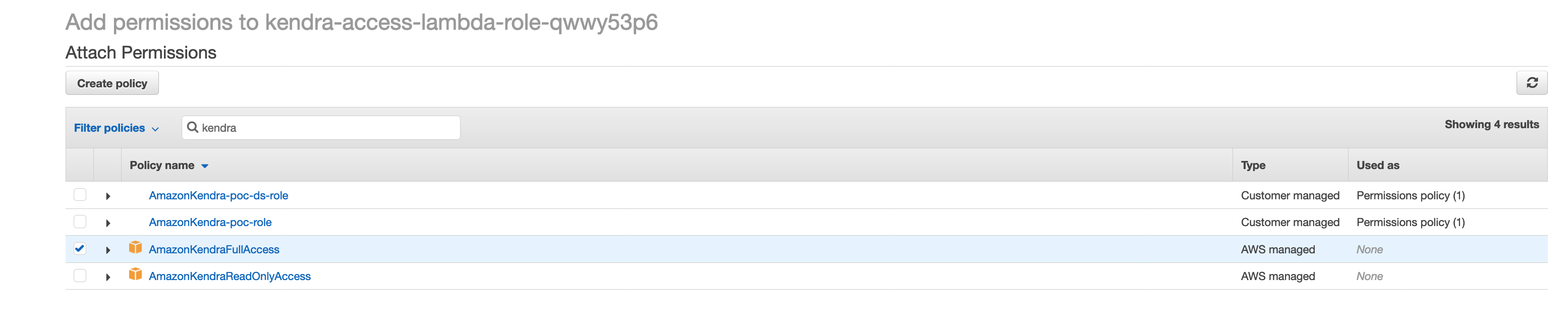
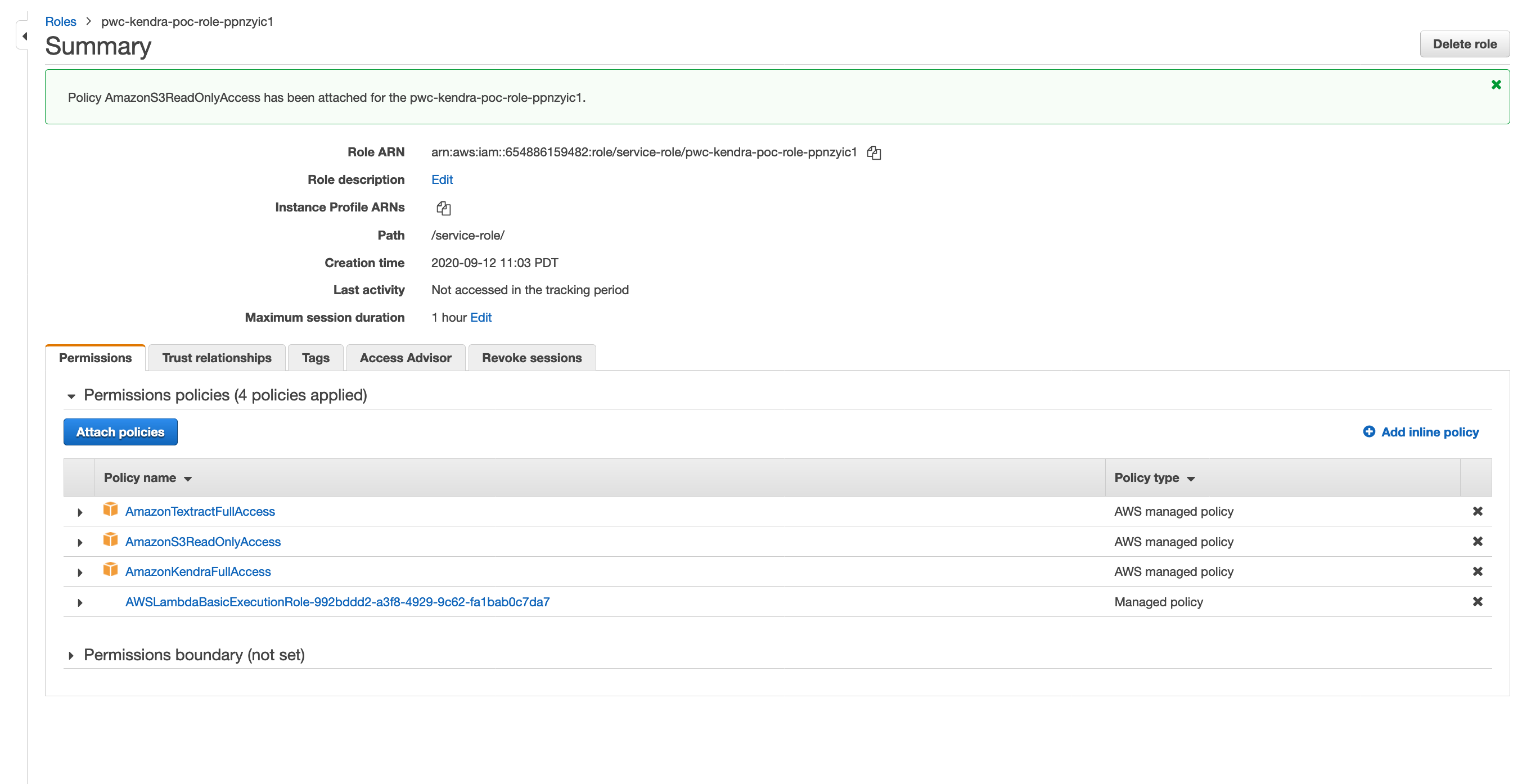
Congratulations! We have completed configuration of the Lambda event handler. Now carry on to create a Cloud9 workspace.